Professional Reference Shelf
Appendix
- Appendix 1: McMaster Five-Point strategy
- Appendix 2: Plotting Data
McMaster Five-Point strategy*

- Define:
- Identify the unknown or stated objective.
- Isolate the system and identify the knowns and unknown laws, assumptions, criteria, and constraints) stated in the problem
- List the inferred constraints and the inferred criteria.
- Identify the stated criteria.
- Explore:
- Identify tentative pertinent relationships among inputs, outputs and unknowns.
- Recall past related problems or experiences, pertinent theories, and fundamentals.
- Hypothesize, visualize, idealize, generalize.
- Discover what the real problem and the real constraints are.
- Consider both short-time and long-time implications.
- Identify meaningful criteria.
- Choose a basis or a reference set of conditions.
- Collect missing information, resources, or data.
- Guess the answer or result.
- Simplify the problem to obtain an "order-of-magnitude" result
- If you cannot solve the proposed problem, first solve some related problems or solve part of the problem.
- Plan:
- Identify the problem type and select among heuristic tactics
- Generate alternative ways to achieve the objective.
- Map out the solution procedure (algorithm) to be used.
- Assemble resources needed.
- Act:
- Follow the procedure developed under the plan phase; use the resources available.
- Evaluate and compare alternatives.
- Eliminate alternatives that do not meet all the objectives or fulfill all the constraints.
- Select the best alternative of those remaining.
- Reflect:
- Check that the solution is blunder-free.
- Check reasonableness of results.
- Check procedure and logic of your arguments.
- Communicate results.
|
*Woods, D.R., A Strategy for Problem Solving, 3rd ed., Department of Chemical Engineering, McMaster University, Hamilton, Ontario, 1985; Chem. Eng. Educ., p. 132, Summer 1979; AIChE Symposium Series, 79 (228), 1983.
Plotting Data
In this appendix, we review the techniques for plotting data and measuring
slopes on various types of graphs. With the aid of many readily available computer
packages, constructing graphs from data is quite straightforward. The background
material in this appendix will help you understand the various types of graphs and
enable you to determine the important parameters from them. Additionally, we
review some statistical techniques available for analyzing experimental data.
Linear Plots
| First, let's look at a quick review of the fundamentals of graph construction and slope measurement on linear plots. Equations of the form |
| y = mx +b |
(A-1) |
| will, of course, yield a straight line when plotted on linear axes. Consider an example where we place $100 in the bank in a simple interest bearing account for five years. A graph of the amount of money in the account at the end of each year is shown below. |
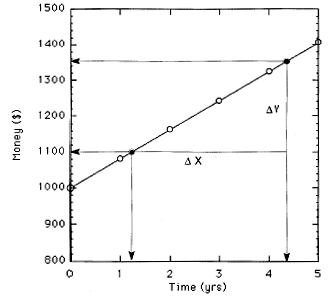 |
| To determine the slope of the line on the graph, we could proceed in two ways. |
Method 1-Direct Measurement
We can physically measure Δx and Δy using a ruler, and then using the linear
scale of the graph, determine the slope of the line. For this example, suppose Δx =
34 mm and Δy = 20 mm. The linear scale for the y-axis is $12.50/mm and for the x-axis
it is (1 yr)/(11 mm). Therefore,
ΔMoney = (20 mm)($ 12.50/mm) = $250
ΔTime = (34 mm)(1yr)/(11 mm) = 3.l yrs
| Slope |
= |
ΔMoney |
= |
$250 |
= |
$81/yr |
| ΔTime |
3.1 yrs |
The intercept ($1000) can be read directly from the graph at time t = 0. While this
method works, it is rather crude and its accuracy is limited by the accuracy of the
measuring devices used.
Method 2 - Direct Calculation from Points on the Line
Pick two points that lie on the line. These points will not necessarily be data
points if the data are scattered.
Point 1: 11.23, 1100)
Point 2: (4.32. 1350)
| Slope |
= |
ΔMoney |
= |
(1350 - 1100) |
= |
$80.9/yr |
| ΔTime |
(4.32 - 1.23) |
The intercept may be determined from either point using the calculated slope and the
equation of the line (y = mx + b , 1100 = (80.9)(1.23) + b , b = 1000 ). As you can
see there is a slight difference in the values of the slopes calculated using the two
different methods. This difference can be attributed to the accuracy with which the
point values can be read from the graphs and the accuracy of the measurements in
Method 1.
Many computer packages are available which can determine the equation of
the "best" straight line through the data points. These programs employ a statistical
technique called regression (or least-squares) analysis. A regression analysis of the
above data yields the following equation for the "best" line through the data points:
| Money ($) |
= |
[$81/yr] |
[Time (yrs)] |
+ |
1000 |
| y |
= |
m |
x |
+ |
b |
Notice the values determined in this manner are very close to those determined
earlier.
Log-Log Plots
When both axes are logarithmic, the graph is called a log-log graph. A log-log graph of the data is used when the dependent variable (u, for instance) is proportional to the independent variable (say, v) raised to some power m:
In many engineering applications, it is necessary to determine the best values of m and B for a set of experimental measurements on u and v,. One of the easiest ways to perform this task is to use logarithms on Equation A-2. If we take the log of both sides of the equation, we get
| log(u) = mlog(v) + log(B) |
(A-3) |
Now, if we let
| y = log(u) |
|
| x = log(v) |
|
| b = log(B) |
|
then Equation (A-3) becomes:
Now we can clearly see that Equation (A-2) has been transformed so that a plot
of log u (y) versus log v (x) will be a straight line with a slope of m and an intercept
of log B. Chemical reaction rate data often follow a log-log relationship. Consider the following reaction rate data:
| |
|
|
|
|
 |
| Concentration, CA (gmoles/dm3) |
1 |
2 |
3 |
4 |
| Reaction Rate (gmoles/dm3/hr) |
3 |
12 |
27 |
48 |
| |
|
|
|
|
If we assume that a log-log plot (Equation A-2) is appropriate here, we can graph these data to determine m and B. There are two ways that we can proceed. We can manually take logarithms of the data and plot those, or we can use log-log coordinates and let the graph do the work. We shall illustrate both methods.
Method 1: Manually taking logarithms (Note: log = log10 in this example)
| log(Concentration) |
0 |
0.301 |
0.477 |
0.602 |
| log(Reaction Rate) |
0.478 |
1.08 |
1.43 |
1.68 |
We now plot these points on linear paper. It is very important to remember that if you manually take logs, you must plot the points on linear paper not log-log paper (otherwise you'll get a mess!).
vsLog(Conc).gif)
Now we can proceed just as we did for the simple linear plot case to determine the slope and intercept of the line and find the parameters for Equation (A-2). The intercept, b, is clearly 0.478 (from the tabular data). Let's determine the slope using two points on the line.
Point 1: (0.38, 1.2)
Point 2: (0.18, 0.8)
| Slope |
= |
1.2 - 0.8 |
= |
m |
| 0.38 - 0.18 |
and since b = 0.478,
b = log B = 0.478
B = 10b = 100.478 = 3
Thus, the equation for the line is
u = Bvm = 3v2
or in terms of concentration and rate
Rate = 3CA2
Method 2: Plotting Directly on Log-Log Paper
Plotting directly on log-log paper is relatively simple. You merely plot the points, and the logarithmic scales on the axes take the logs for you. The rate versus concentration data are plotted below on log-log axes.
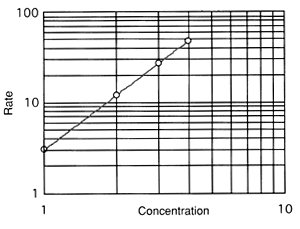
Notice that we again obtain a straight line. These types of plots are more meaningful to the reader, because the points that are plotted correspond to the actual numerical values of the data, and not the logarithms of the data. From the plot. the reader can determine immediately that the concentration value associated with the second data point is 2 gmole/dm3. This physical intuition is not available when the logarithms of the data are plotted on a linear scale (e.g., we would know the log of the concentration is 0.303, but we wouldn't know the concentration itself. unless we could perform antilogs in our heads). So now how do we determine the slope and "intercept" from this type of a plot? If Equation (A-3) is a valid equation for the line, then it should hold for every point on the line. Writing this equation for two arbitrary points on the line, we get
| log(u1) = log(B) + mlog(v1) |
Point 1 |
(A-5) |
| log(u2) = log(B) + mlog(v2) |
Point 2 |
If we subtract the equation for point 2 from that of point 1, we'll get an expression that will allow us to calculate the slope of the line on the log-log axes.
| log(u1) - log(u2) = m[log(v1) - log(v2)] |
|
| m |
= |
log(u1/u2) |
or, for this example |
m |
= |
log(Rate1/Rate2) |
| ‾‾‾‾‾‾‾‾‾‾ |
‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾ |
| log(v1/v2) |
log(CA1/CA2) |
Once the value of m is determined, B can be found by substituting the appropriate values for either point back into Equation (A-5).
| m |
= |
log(48/3) |
= |
1.204 |
= |
2 |
| ‾‾‾‾‾‾‾‾‾ |
‾‾‾‾‾‾ |
| log(4/1) |
0.602 |
log(B) = log(48) -2*log(4) = 0.477
B = 3
Notice that this is the same result that we arrived at previously, as it should be.
We can also determine the slope of a line on log-log axes using the direct
measurement technique, as discussed in the section on linear plots. With the
availability of computer graphing packages this method is not used very much, but
we include it here for completeness. To measure the slope directly using a ruler or
similar instrument, we would choose two points on the line. and measure ΔY and Δy
and the cycle length in both directions and proceed as follows.
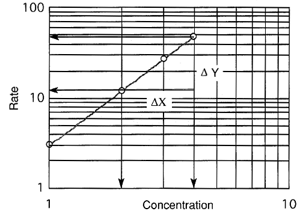 Δy = 2.55 cm
Δy = 2.55 cm
Cycle length in the y-direction = 3.6 cm/cycle
Δx = 1.55 cm
Cycle length in the x-direction = 4.35 cm/cycle
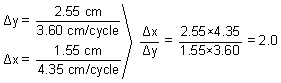 y = bx2
y = bx2
and, using the point, (x =1, y =3), we can determine the value of b:
3 = b(1)2, b = 3
y = 3x2
rate = 3CA2
Again, this is the same result we obtained earlier.
Semi-Log Plots
Semi-logarithmic (semi-log) plots should be used with exponential growth or decay equations of the form
| y = bemx or y = b(10)mx |
(A-6) |
To determine the parameter,. b and m , we take logarithms of both sides of Equation (A-6). We'll use the "e" form of the equation and natural logarithms (ln), although the result is the same for the other form of the equation using common (base 10) logarithms.
Examining Equation (A-7) we see that a plot of ln(y) versus x should be a straight line with a slope of m and an intercept of b. If we deposit $100 into a bank account that gathers interest compounded continuously (a great deal!). and then plot the amount of money in the account at the end of every year for the first ten years, we obtain the following graph:
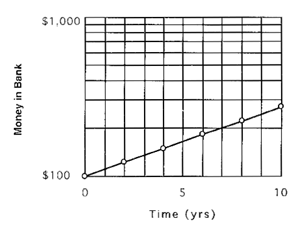
Notice that we have plotted the data (for every other year) directly on semi-log paper. We could have manually taken the logs and plotted the data on linear paper as discussed earlier, but using semi-log axes is easier. We show two methods to determine the parameters of Equation (A-6) from the semi-log plot.
Method I: Algebraic Method
Draw the best straight line through your data points. Choose two points on this line and determine the x and values of each point.
Point 1: (8 yrs, $223)
Point 2: (2 yrs, $122)
Notice that we can write Equation (A-7), using the two points and solve for the slope.
ln(y1) = ln(b) + mx1
ln(y2) = ln(b) + mx2
ln(y1/y2) = ln(x2 - x1)
| m |
= |
ln(y1/y2) |
| ‾‾‾‾‾‾‾‾‾ |
| (x2 - x1) |
Substituting the values of the selected points, we get
| m |
= |
ln(223/122) |
= |
0.1 |
| ‾‾‾‾‾‾‾‾‾ |
| (8 - 2) |
Substituting the values of the selected points, we get m = ln[223/122]/(8-2) = 0.1, and
then b is clearly the y value of the line at time t = 0, i.e., be0.1(0) = b, thus b = 100
Amount ($) = $100e0.1*Time(yrs)
Method 2: Graphical Technique
A modification of the algebraic method is possible on semi-log paper if we extend the "best" line we can draw so that the dependent variable, y, changes by a factor of 10. For this case. the ratio of y2/ y1 is 10 and the equation for the slope of the line is merely:
| m |
= |
ln(10) |
= |
2.303 |
| ‾‾‾‾‾‾‾‾‾ |
‾‾‾‾‾‾‾‾‾ |
| x2 - x1 |
x2 - x1 |
The intercept can then be determined as before. This technique is referred to as the decade method. Careful analysis and plotting of the data are important tools in problem solving. In addition to being able to calculate the slopes and intercepts, we should be able to deal with "scatter" in the data. The next section discusses this topic.
Establishing Confidence Limits for Data
Normally, the data we wish to analyze are the results of some type of
experiment. There will often be some "scatter" or variability in the data. If an
experiment is repeated a number of times, chances are the results will have some
variation. These variations are due to experimental error, instrument precision,
material variability, etc. One approach to dealing with this situation is to perform
several experimental runs under identical conditions and average the results. Intuitively, we realize that the more runs we perform, the closer the average of our experiments will approach the true average for the experimental conditions under consideration. In fact, if we performed an infinite number of repetitions, we would expect to obtain the true average as a result of this hard work. Since we cannot afford to perform an infinite number of experiments to determine the true mean of these experiments (μ = true mean) we would like to have a way to estimate it from a limited number of samples. Let's define the following quantities:
μ = true mean of the experiments (i.e., population) if a very large (∞) number are performed
n = sample size (the number of experiments that we actually performed)
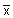 = mean of the n samples = ∑ x / n
= mean of the n samples = ∑ x / n
The standard deviation of the samples quantifies the spread of the sample values about the sample mean. The bigger the standard deviation, the larger the variability of the individual samples. We can estimate the standard deviation of the entire population (from which we have measured n samples) using Equation (A-8):
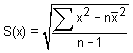 |
(A-8) |
Note, to determine the true standard deviation (σ) of the entire population, we would have to know μ, the true mean (which we don't). So, we estimate the standard deviation.
As an example of a distribution, consider the following. We could gather some data regarding the length of time beyond the bachelor's degree that it takes a student at Frostbite Falls University to complete a Ph.D.. If we plotted the data, it might look like the following figure.
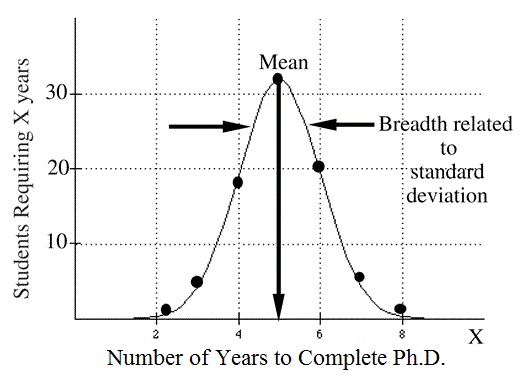
The mean time to obtain a Ph.D. is five years, and there is clearly a distribution about the mean, which is to be expected. Almost no students take less than two years or longer than eight years. The breadth of this "distribution" is related to the standard deviation.
If we draw several different samples of size n from the entire population, and calculate the mean for each, we will most likely get a different mean, , for each sample. Additionally, none of these means will probably be equal to the true mean of the entire population, μ. In other words, we will get a distribution of means that is related to the true mean μ. The variability of these means is related to the variability of the entire population (i.e., to the standard deviation).
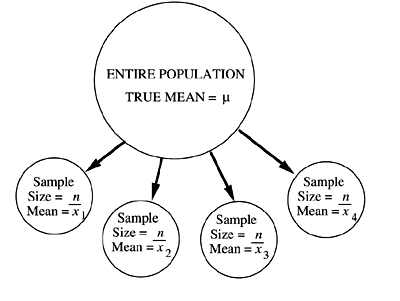
Let S () represent the estimated standard deviation of the means of samples of size n drawn from the entire population which has an estimated standard deviation of S(x) (that we previously calculated).
These quantities are related in the following manner:
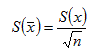 |
(A-9) |
We noted that is an estimate of the true mean (μ) of the experiments. But how good an estimate is it? One way to express this relationship is
| μ = ± tS() |
(A-10) |
This equation states that the true mean lies within t S() of the estimated mean, . The quantity "t" is calculated from the so-called t distribution. "t" is a function of two parameters: a confidence level and the degrees of freedom. The degrees of freedom in our context is (n-1) where n is the number of experiments performed under a given set of conditions. For a set of experiments, the number of degrees of freedom that we have to model the data is n, the number of runs. For this case, we have used one degree of freedom to calculate the mean. Thus there are only (n-1) degrees of freedom remaining. Another way to look at this is that we can specify (n-1) data points independently, and then the nth value is fixed, since we have already determined the mean value of the data set. The confidence level is defined as the probability that t is smaller than the tabulated value. Below is an excerpt from a table of the t distribution:
| Degrees of Freedom |
95% Confidence Level |
95% Confidence Level |
| 1 |
12.706 |
63.657 |
| 2 |
4.303 |
9.925 |
| 3 |
3.182 |
5.841 |
| 4 |
2.776 |
4.604 |
| 5 |
2.571 |
4.032 |
| 6 |
2.447 |
3.707 |
| 7 |
2.365 |
3.499 |
| 8 |
2.306 |
3.355 |
| 9 |
2.262 |
3.250 |
| 10 |
2.228 |
3.169 |
In essence, the confidence level will tell us how certain we can be that the mean of
our data points will lie within the calculated range. For example, with a 95%
confidence level, the means will lie within the range in 95% of the cases, and outside
the range in 5% of the cases.
An example will help here. Consider an experiment where we pop popcorn
using a certain method. We make five runs under identical conditions and obtain the
following data:
| Run No. |
% Unpopped Kernels of Popcorn |
|
| 1 |
22 |
| 2 |
18 |
| 3 |
19 |
| 4 |
26 |
| 5 |
25 |
(Population Size)
n =5
(Estimated Mean)
= ∑x/5 = 110/5 = 22
(Estimated standard deviation of the individual points from the estimated mean)
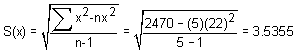 (Estimated standard deviation of the sample means from the true mean)
(Estimated standard deviation of the sample means from the true mean)
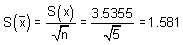 Now to estimate the true mean, we'll use Equation (A-10):
μ = ± tS() = 22 ± 1.51t
Now to estimate the true mean, we'll use Equation (A-10):
μ = ± tS() = 22 ± 1.51t
For four degrees of freedom (n - 1 = 4), we can be 95% confident that t ≤ 2.776 (see the table of t values). Similarly, we can be 99% confident that t ≤ 4.604. Hence,
μ = 22 ± 1.581(2.571) = 22 ± 4.39 (with 95% confidence)
or
μ = 22 ± 1.581(4.032) = 22 ± 7.28 (with 99% confidence)
Note that the more confidence with which we want to specify the mean, the larger
the "error bars" become, or the larger n must be for the same size uncertainty. Data
points can be plotted using these values to indicate the uncertainty in the measurement.
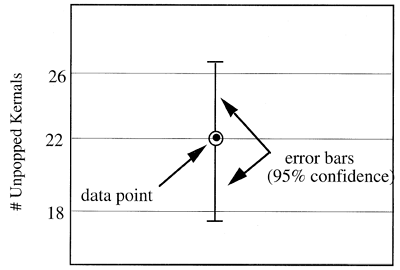
More extensive listings of the t distribution can be found in numerous texts on
statistics.
| References: |
Volk, William, Applied Statistics for Engineers, 2nd ed., McGraw-
Hill, New York, 1969. |
| |
Glantz. Stanton A., Primer of Biostatistics, 3rd ed., McGraw-Hill
Health Professions Division, New York, 1992. |
Presentation of Data

The data that we gather, when properly organized, analyzed and presented will help serve as the basis for subsequent decision making. In order to be of maximum use for problem-solving purposes, organization and presentation of the information are very important. Drawings, sketches, graphs of data, etc. can all be effective communication tools when used properly. Try to display and analyze the data in such a manner so as to extract meaningful information. When presented with data, analyze it to make sure it has not been biased to lead you in the wrong direction.
Display the data graphically rather than in tabular form. Tables can be difficult to interpret and sometimes terribly misleading, as demonstrated by Anscombe's Quartet1,2 shown on below. Graphing, on the other hand, is an excellent way to organize and analyze large amounts of data.
From a statistical standpoint (using a regression analysis on the tabular information) all the data sets are described equally well by the same linear model. However, upon graphing the data, we see some very obvious differences. The graphical presentation clearly reveals the differences in the data sets, which may have gone unnoticed if we had used only the tabular data.
Anscombe's Quartet Table
| Set A |
Set B |
Set C |
Set D |
| X |
Y |
X |
Y |
X |
Y |
X |
Y |
| 10.0 |
8.04 |
10.0 |
9.14 |
10.0 |
7.46 |
8.0 |
6.58 |
| 8.0 |
6.95 |
8.0 |
8.14 |
8.0 |
6.77 |
8.0 |
5.76 |
| 13.0 |
7.58 |
13.0 |
8.74 |
13.0 |
12.74 |
8.0 |
7.71 |
| 9.0 |
8.81 |
9.0 |
8.77 |
9.0 |
7.11 |
8.0 |
8.84 |
| 11.0 |
8.33 |
11.0 |
9.26 |
11.0 |
7.81 |
8.0 |
8.47 |
| 14.0 |
9.96 |
14.0 |
8.10 |
14.0 |
8.84 |
8.0 |
7.04 |
| 6.0 |
7.24 |
6.0 |
6.13 |
6.0 |
6.08 |
8.0 |
5.25 |
| 4.0 |
4.26 |
4.0 |
3.10 |
4.0 |
5.39 |
19.0 |
12.50 |
| 12.0 |
10.84 |
12.0 |
9.113 |
12.0 |
8.15 |
8.0 |
5.56 |
| 7.0 |
4.82 |
7.0 |
7.26 |
7.0 |
6.42 |
8.0 |
7.91 |
| 5.0 |
5.68 |
5.0 |
4.74 |
5.0 |
5.73 |
8.0 |
6.89 |
Statistically everything looks the same!!
Each of these four data sets A, B, C, and D all have the following properties:
| N = 11 |
Mean of X's = 9.0 |
Equation of regression line: Y = 3 + 0.5 X |
| t = 4.24 |
Mean of Y's = 7.5 |
Standard error of estimate of slope = 0.118 |
| r2 = 0.67 |
Correlation coefficient = 0.82 |
Sum of squares 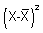 = 0.118 = 0.118 |
| Regression sum of squares = 27.50 |
Residual sum of squares of Y = 13.75 |
Everything looks different!!
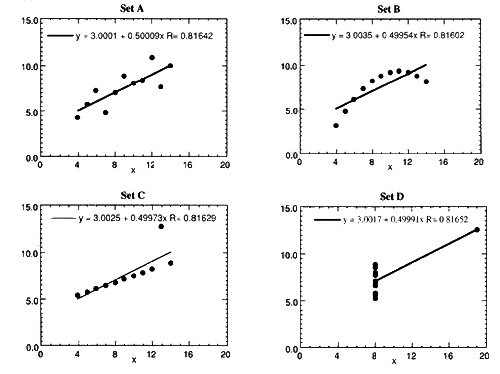
Plots of Data Sets with Same Statistical Properties
1Tufte, E., Visual Display of Quantitative Information, Graphics Press, Cheshire, CT, 1983.
2Anscombe, F. J., "Graphics in Statistical Analysis," Amer. Statisticians, 27, p. 14-21,
Feb. 1973.
Getting the Most Out of Your Data: Grouping the Variables
Sometimes a particular quantity that we are interested in measuring is
dependent upon a number of different variables. Let's consider the flow of fluid
through a pipe at low velocities. Under special low-flow conditions the flow is
termed laminar. We perform a number of experiments and determine that the
pressure drop through the pipe depends upon a number of different parameters: the
diameter of the pipe, the density of the liquid, the velocity of the liquid and the
viscosity of the liquid. (The viscosity is a physical property of the liquid. It is related
to how "thick" the liquid is. For example, maple syrup is more viscous than water,
and molasses is more viscous than maple syrup.)
We can graph the data that we have
obtained on separate graphs. That is, we can graph how pressure drop varies with
fluid velocity. while we hold all the other variables constant. Then, we could graph
pressure drop versus pipe diameter. while holding everything else constant. In this
way we would generate a series of four individual graphs.
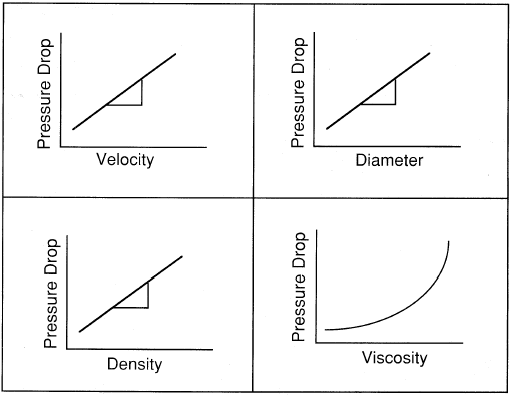
However, if we carefully analyze the physics of the situation, we may be able
to determine a grouping of the variables that would provide us with all the
information that we have available in a single graph. The variable that serves this
function for fluid flow through a pipe is the Reynolds Number, which is defined as
follows:
|
|
(Density)(Velocity)(Diameter) |
| Reynolds Number |
= |
_________________________________ |
|
|
(Viscosity) |
Now, if we process the experimental data into the form of pressure drop versus
Reynolds number arid graph the results, we find that we obtain a single graph that
gives us the same information as the above four graphs.
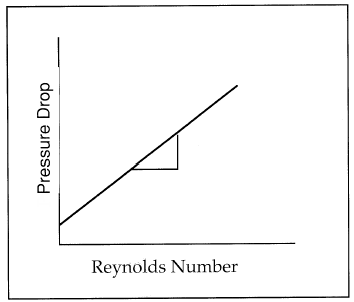
Proper selection of the grouping of the variables will not necessarily be known ahead
of time, but if you are aware of this possibility. you may be able to condense your data
into a more usable format.
References
1. Tufte, E., Visual Display of Quantitative Information, Graphics Press, Cheshire, CT, 1983.
2. Anscombe, F. J., “Graphics in Statistical Analysis,” American Statisticians, 27, pp. 14–21, February 1973.
Further Reading
Glantz, Stanton A. Primer of Biostatistics, 3rd ed. McGraw-Hill Health Professions Division, New York, 1992.
Volk, William. Applied Statistics for Engineers, 2nd ed. McGraw-Hill, New York, 1969.